
The Full Text Search application allows end users to quickly filter across all columns within a given web application. Additionally, to help with the performance of these applications, all data queried is first loaded onto the m-Power server via the SOLR engine. This process is called indexing and is required. You can try a live demo by clicking here.
Configuring the SOLR engine
On the m-Power server, please download and extract this zip file. You can choose where the folder is extracted. For the sake of this documentation, we will assume it has been extracted to c:\solr-7.4.0. [Customers hosting m-Power on a Linux server should see the Linux based directions at the end of this document].
Once the folder has been extracted, navigate to /mrcjava/WEB-INF/classes/mrc-runtime.properties
Add the following two lines to the file:
mrc_solr_server_base=C:/solr-7.4.0
mrc_solr_server_ip=http://localhost:8983
Adjust the SOLR folder property to point to the actual folder. The ip address should reference the server’s appropriate http/https protocol, localhost and 8983 (the default SOLR port).
Now that SOLR has been configured, it needs to be started. Open a command window and navigate to SOLR’s bin folder, such as:
cd c:\SOLR-7.4.0\bin
Next type “solr start”
This will start the SOLR service.
(Note: This command can be scheduled so it starts immediately after a Windows reboot).
After saving and restarting Tomcat, we need to register the Full Text Search template to m-Power. To accomplish this, navigate to the m-Power interface screen, sign in, and click “Admin.” Next, click “Templates” then “Manage Templates. Click “Create New Template.” Specify the following:
Template Type: Retrieval
Template #: Any available number
Description: Full Text Search
Preview Program: PREVIEWINQ
Save the Template. Next Find the template you just created and click “View Files” and then click “Create New Template File”. Match your configuration to the following image (Make sure your Template # matches what was set above):
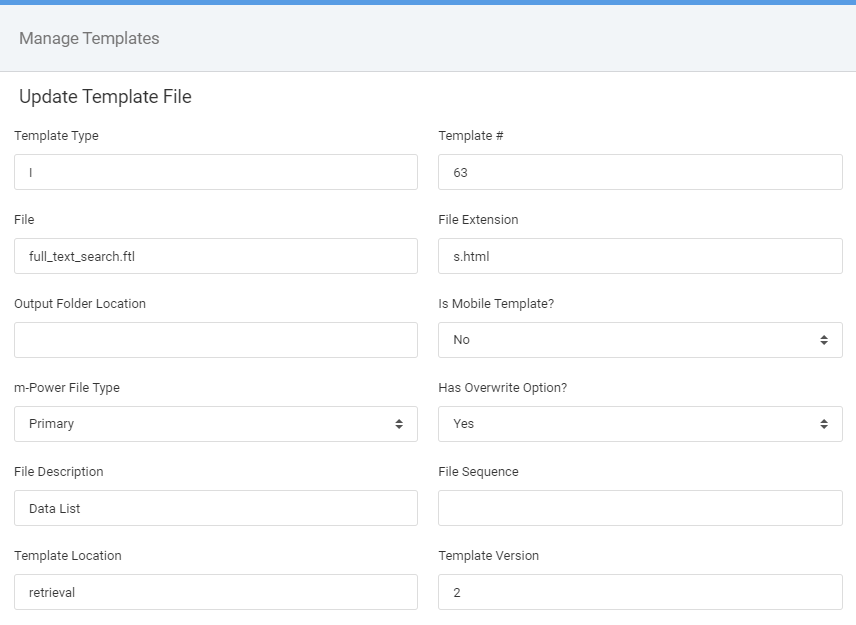
Repeat the steps for the following two additional template files:
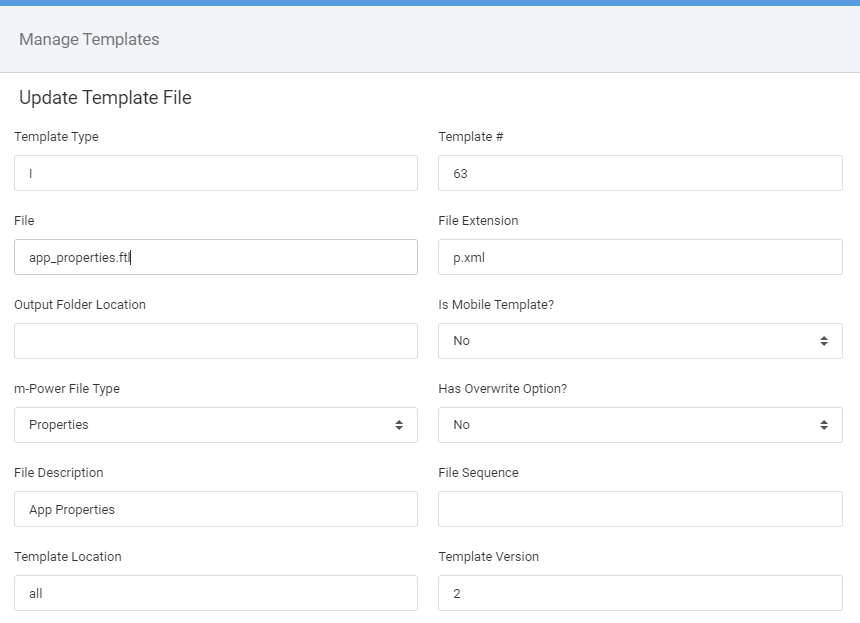
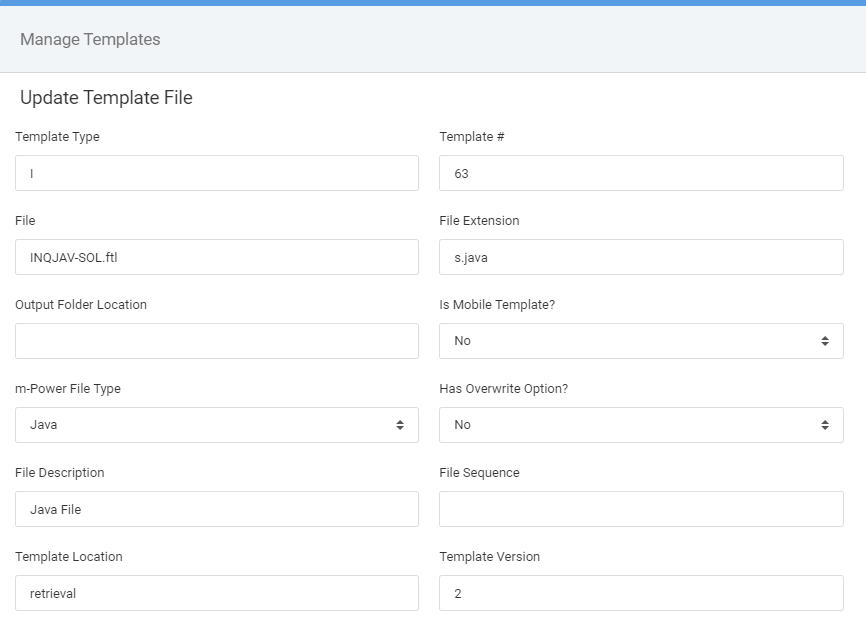
You’ve successfully installed and configured the SOLR Component. Next we will turn our attention to using the Full Text Search template.
Using the Full Text Search Template
Building a Full Text Search application is identical to building any other Retrieval based application. A few things to remember:
- Be sure to select the Full Text Search template
- When selecting your Sequencing keys, be sure to sequence by a combination of fields that ensure the uniqueness of your dataset. Any records that share sequence key values will be omitted from the dataset.
- External objects and row level security are not supported in this template.
After building the application, you will run it and see a screen that looks like this:
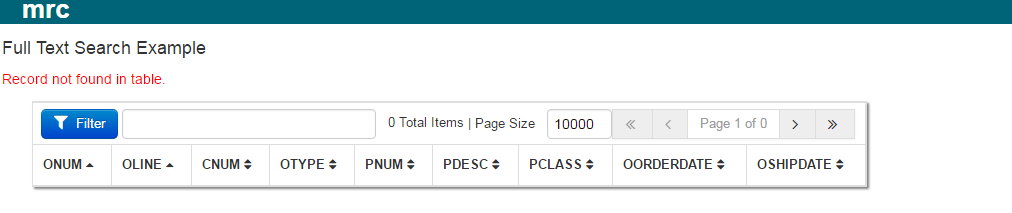
This page indicates that no data is available in the SOLR database. To load data to it, append “?index=1” to the URL and press enter. When processing is completed, a screen will appear showing you how many records (documented) were indexed. Re run the application without the ?index=1 to show your data.
Behind the scenes, m-Power has just queried your database and processed all records found into the SOLR database. All future requests made by this application will query the SOLR database (located on your m-Power server) and not your live database. This architecture is what supports the full text search as well as allowing for better application performance. However, it is important to know that the data queried by this application will be stagnant until this dataset has been refreshed (by re-running index=1 or by scheduling the index refresh).
When using the Search component, all columns in the application are subject to the search. Please note that the search uses a Full Text Search. That means that only results will be found when a full word is found, not a partial match. For example, entering in “Calif” would not return any records for a list of states, where entering “California” would.
Scheduling Data to be Refreshed
While appending ?index=1 to your URL is useful during testing, for a production environment, you will want to schedule your datasets to refresh regularly. To do this, take advantage of the Messaging and Scheduled Tasks function of m-Power.
Head to Admin Menu -> Utilities -> Messaging and Scheduled Tasks. Create a new Task and select “Full Text Search Index.” Select Your Dictionary then select the SOLR dataset you wish to refresh. Press Save. Finally, schedule the Task Group as you would any other task group.
Installation on Linux
In the event you wish to install this on an m-Power instance hosted on Linux, please amend the above to include the following:
- After extracting the folder, run the following:
sh /solr-7.4.0/bin/install_solr_service.sh /path/to/solr/zipfile - Edit the /etc/init.d/solr file so that the SOLR_INSTALL_DIR property is set to “/opt/solr”
- After saving, start SOLR by running this command: service solr start
Additionally, customers running on Linux will need to delete the file “hive-jdbc-1.1.0-standalone.jar” within /tomcat/lib.